
燧原科技推出中国最大AI计算芯片
微电子制造 讯2021年7月7日,在2021世界人工智能大会期间,上海燧原科技推出第二代云端AI训练芯片邃思2.0及训练产品云燧T20/T21,以及全新升级的驭算Topsrider 2.0软件平台。邃思2.0是迄今中国最大的AI计算芯片,采用日月光2.5D封装的极限。燧原科技作为一家专注人工智能领域云端算力平台,开发自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品的企业,燧原科技自2018年成立以来,就获得了多家领先资本的青睐。

邃思2.0实物图
“我们新发布的邃思2.0是中国最大的计算芯片,与竞争对手的最新旗舰相比,邃思2.0也毫不逊色”,燧原科技COO张亚林在发布会上强调。据他介绍,燧原科技的新一代芯片采用了2.5D封装,在其中整合了9颗芯片。这样的设计也使得整个芯片的整体封装尺寸做到了惊人的57.6mm×57.6mm,达成国内领先的成就。
据介绍,邃思2.0进行了大规模的架构升级,采用了新一代全自研的GCU-CARA全域计算架构,针对人工智能计算的特性进行深度优化,夯实了支持通用异构计算的基础;支持全面的计算精度,涵盖从FP32、TF32、FP16、BF16到INT8,并成为中国首款支持单精度张量TF32数据精度的人工智能芯片。单精度FP32峰值算力达到40 TFLOPS,单精度张量TF32峰值算力达到160 TFLOPS,以上数据均为国内第一。

此外,通过对HBM2E存储的采用,燧原科技让“邃思2.0”拥有了海量的吞吐能力,邃思2.0共搭载了4颗HBM2E片上存储芯片,高配支持64 GB内存,带宽达1.8 TB/s。值得一提的是,“邃思2.0”是中国第一颗支持世界最先进存储HBM2E和单芯片64 GB内存的产品。
加速卡云燧T20/T21
在发布邃思2.0的同时,邃原科技也发布了训练芯片,加速卡云燧T20/T21。张亚林表示,公司的下一代训练芯片将在2023年面世,每瓦性能会比邃思2.0提升两倍。
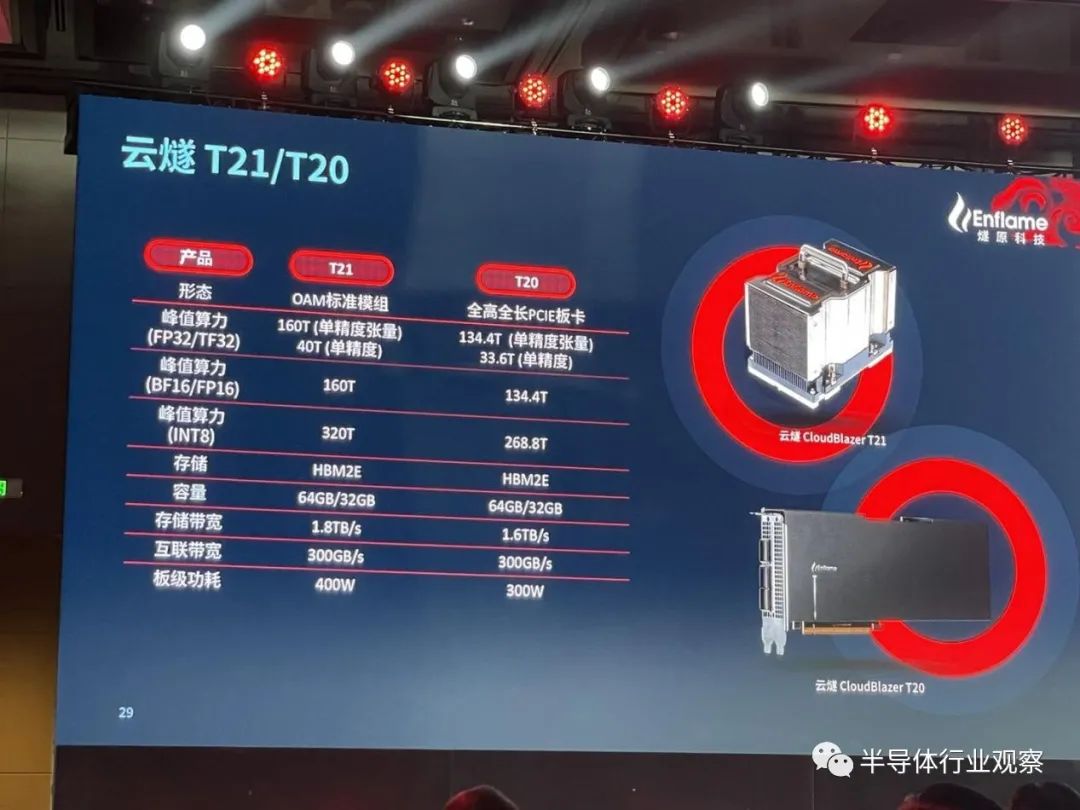
如上图所示,燧原科技第二代通用人工智能训练加速卡“云燧T20”是一个全高全长的PCIE板卡,在FP 32/TF 32下的峰值算力可以做到134.4T(单精度张量)和33.6T(单精度)。在BF16/FP16下的峰值算力则能做到134.4T。INT8的峰值算力更是达到了268.8T,相当于友商的旗舰水平。
采用OAM模组模式设计的云燧T21,如上图所示,各项数据都非常优秀。
驭算TopsRider架构
硬件之外,燧原科技同样注重软件的更迭,发布了驭算TopsRider架构2.0系列,促进软硬件更好协调发展。
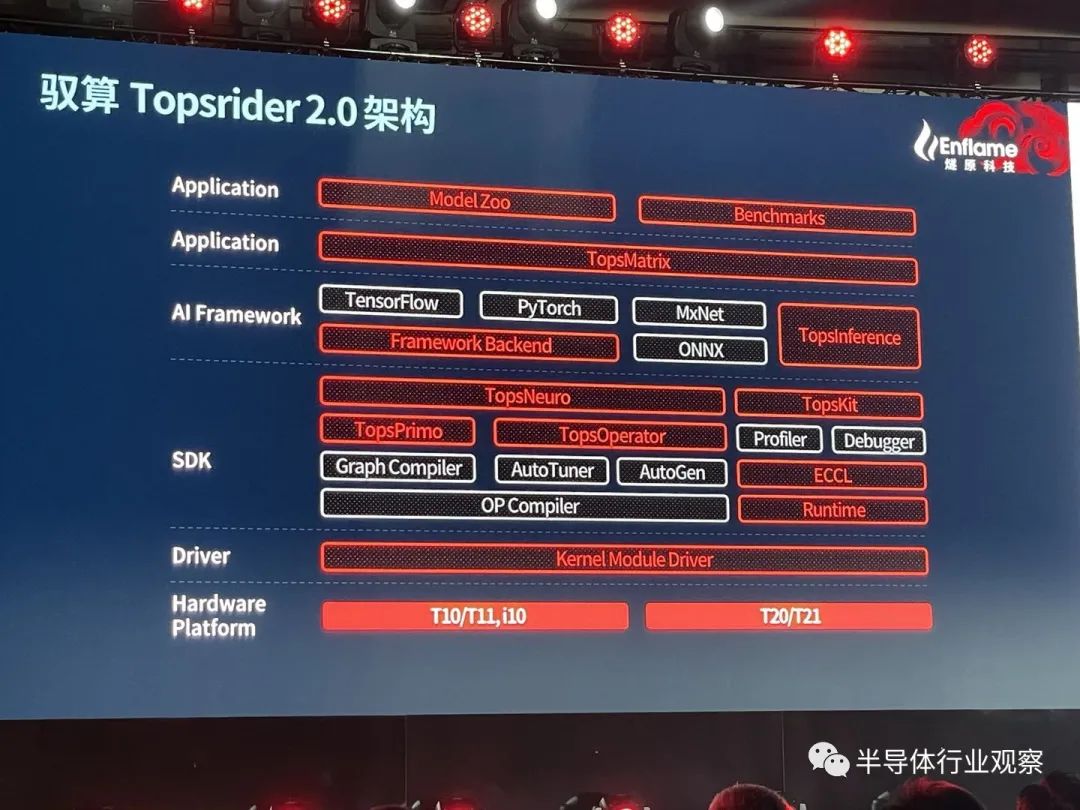
燧原方面表示,通过软硬件协同架构设计,全新的驭算TopsRider能够充分发挥邃思2.0的性能;基于算子泛化技术及图优化策略,能支持主流深度学习框架下的各类模型训练;再通过利用Horovod分布式训练框架与GCU-LARE互联技术相互配合,为超大规模集群的高效运行提供解决方案。开放升级的编程模型和可扩展的算子接口,为客户模型的优化提供了自定义的开发能力。
除了在计算能力上有了大幅度的提升,燧原科技同时还在互联与软件上同步投入,这让公司能够在降低开发者开发门槛的同时,还能提升板卡在系统中的性能。
据介绍,燧原在新产品中引入GCU-LARE全域互联技术,作为一项公司专为人工智能训练集群研发的互联技术,GCU-LARE能提供双向300 GB/s互联带宽,支持数千张云燧CloudBlazer加速卡互联,实现优异的线性加速比.
云燧计算集群
在发布两款加速卡的同时,燧原还介绍了一个基于公司训练卡打造的超大规模智算集群。

张亚林告诉记者,这个名为云燧智能集群(CloudBlazer Matrix 2.0)的产品包含了8192张云燧训练卡,可实现最高1.3E的算力,是全球独一无二的。“这代表着燧原正使用集群化产品登上中国智能计算和新基建算力舞台”,张亚林强调,“燧原科技可以打造超大规模的集群产品CloudBlazer Matrix,有效降低人工智能超算集群的整体复杂度和成本,同时通过与合作伙伴的联合开发,一起构建超大规模的液冷智能数据中心,以响应国家‘低碳算力’和‘绿色一体化智能计算’的战略方向。“
从当前的行业现状看来,无论是在云端AI芯片,还是云端推理芯片,都拥有巨大的成长潜力。有待相关从业者把握机会,推动新的变革与发展。
微信扫一扫,一键转发

